Understanding Harness Engineering Through the Lens of Context
Many things advertised as “new” are often just solid engineering practices applied to a new problem space. The real progress does not come from renaming old ideas. It comes from actually building systems, seeing where they break, and learning from the constraints that only practice can expose.
When I think about Harness Engineering, I find it more useful to anchor the discussion in two concrete engineering essays:
- OpenAI’s article: https://openai.com/zh-Hans-CN/index/harness-engineering/
- Anthropic’s article: https://www.anthropic.com/engineering/harness-design-long-running-apps
If we only look at the phrase itself, we can translate or interpret it in many ways:
- “Harness Engineering” as a literal translation
- Agent orchestration and integration
- Building the workspace in which an agent can operate
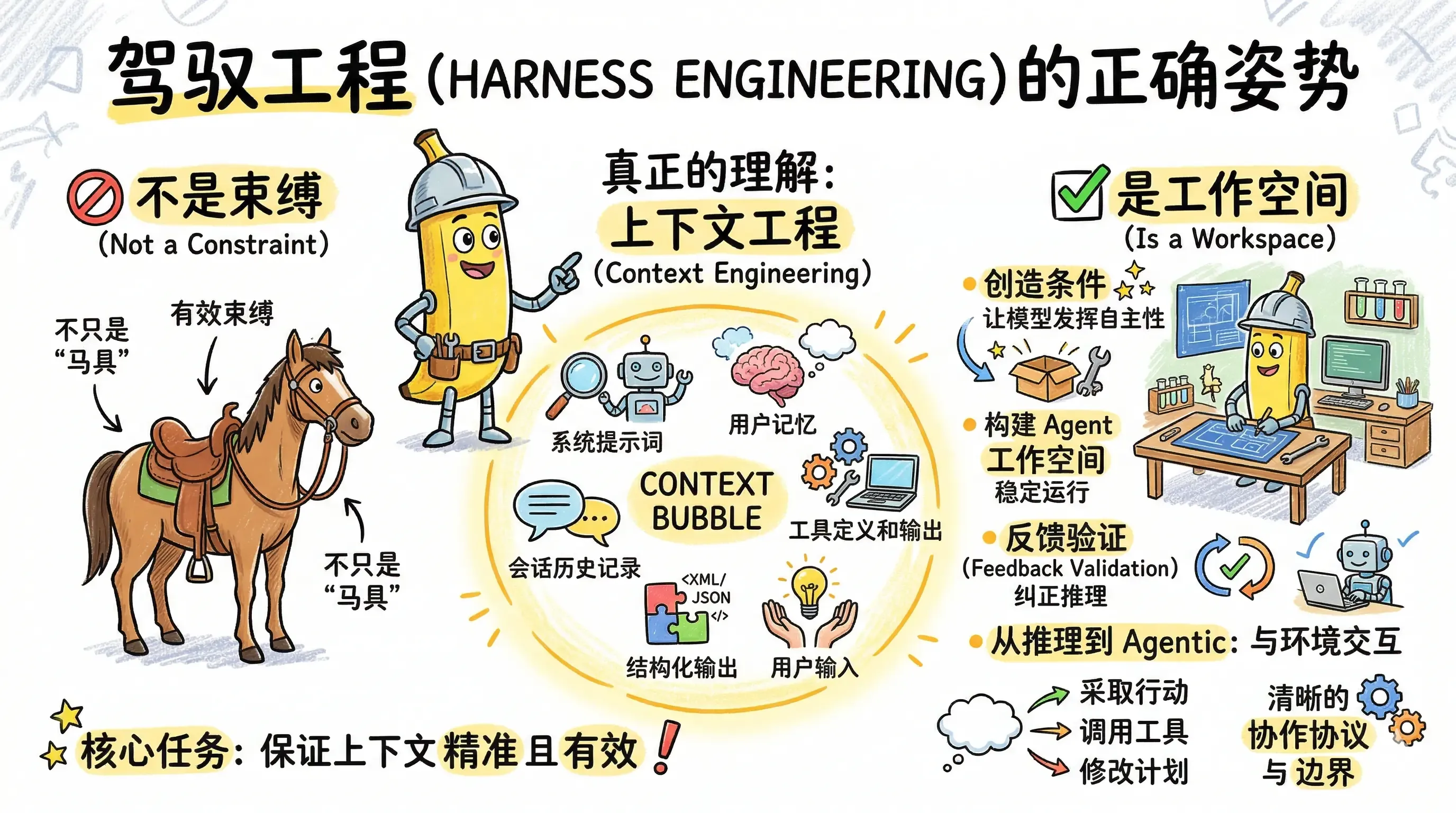
1. Why “Harness” Should Not Be Reduced to Control
Personally, I have never loved explanations that reduce “harness” to reins, saddles, and control mechanisms.
One common explanation goes roughly like this:
A harness is what lets you control a powerful horse. A model is also powerful, but it needs the right equipment before it can do useful work.
I understand the metaphor, but I also think it easily leads people in the wrong direction. It frames the problem as one of restraining the model, as if the core job were to limit it tightly enough that it behaves.
That mindset reminds me of an earlier phase of agent building, when people relied heavily on workflow-based systems. Developers would encode their understanding of a business process into a rigid execution skeleton, and the agent could only move along that skeleton. Systems like that can be useful. They can even be practical. But they rarely unlock the full autonomy or potential of the model.
Real business environments are messy. User inputs are uncertain. The environment keeps changing. A pure workflow is rarely enough to carry the whole burden of domain innovation.
As models improve, that same skeleton can become more of a constraint than a help. That does not mean workflows were meaningless. Quite the opposite: workflows were an important stage in the history of LLM application engineering. They helped the field make real progress.
At the time, prompt engineering also sat behind much of that work. Many people believed that the secret to building a strong agent was to write a perfect system prompt, rather than to approach the problem with a broader engineering mindset.
When context engineering entered the conversation, it felt like a breakthrough. It made me feel that LLMs had a much better chance of landing in real domains and real products. When I look at products like Cursor, Claude Code, Lovart, or Youmind, I can clearly see the influence of context engineering in how they are built.
And I think our understanding of context engineering should be even broader than that, because “context” can serve as a core organizing principle for LLM applications as a whole.
Context engineering is the practice of selecting, organizing, and injecting information that is highly relevant to the user’s input or task within a limited context window, so that an LLM can reason and act as effectively as possible within realistic constraints.
That is why I worry about the “horse harness” interpretation. It can confuse developers and push the ecosystem toward a less productive mental model. So I want to describe Harness Engineering through the lens of context engineering instead. To me, that framing is much more useful.
2. My Path Toward Understanding Context
Before getting into Harness Engineering directly, I want to explain how I arrived at this way of thinking about context in the first place.
I build LLM applications in my own time, and I also spend a lot of time trying to understand the ideas behind products and frameworks in the market. Why did they choose one technique over another? What role is that technology really playing? How does it fit into the larger system?
At some point, it all started to feel overwhelming. There were too many concepts, too many frameworks, and too many partial explanations.
Then one afternoon, I ran into the idea of context again, and something clicked. When I thought back to my own experience building agents, I realized that the decisive factor was often the context available at the moment the task was injected. Whether an agent produced a useful result depended heavily on whether the injected context was accurate, relevant, and well organized.
Once I started following that line of thought, many engineering ideas suddenly connected into a single coherent map:
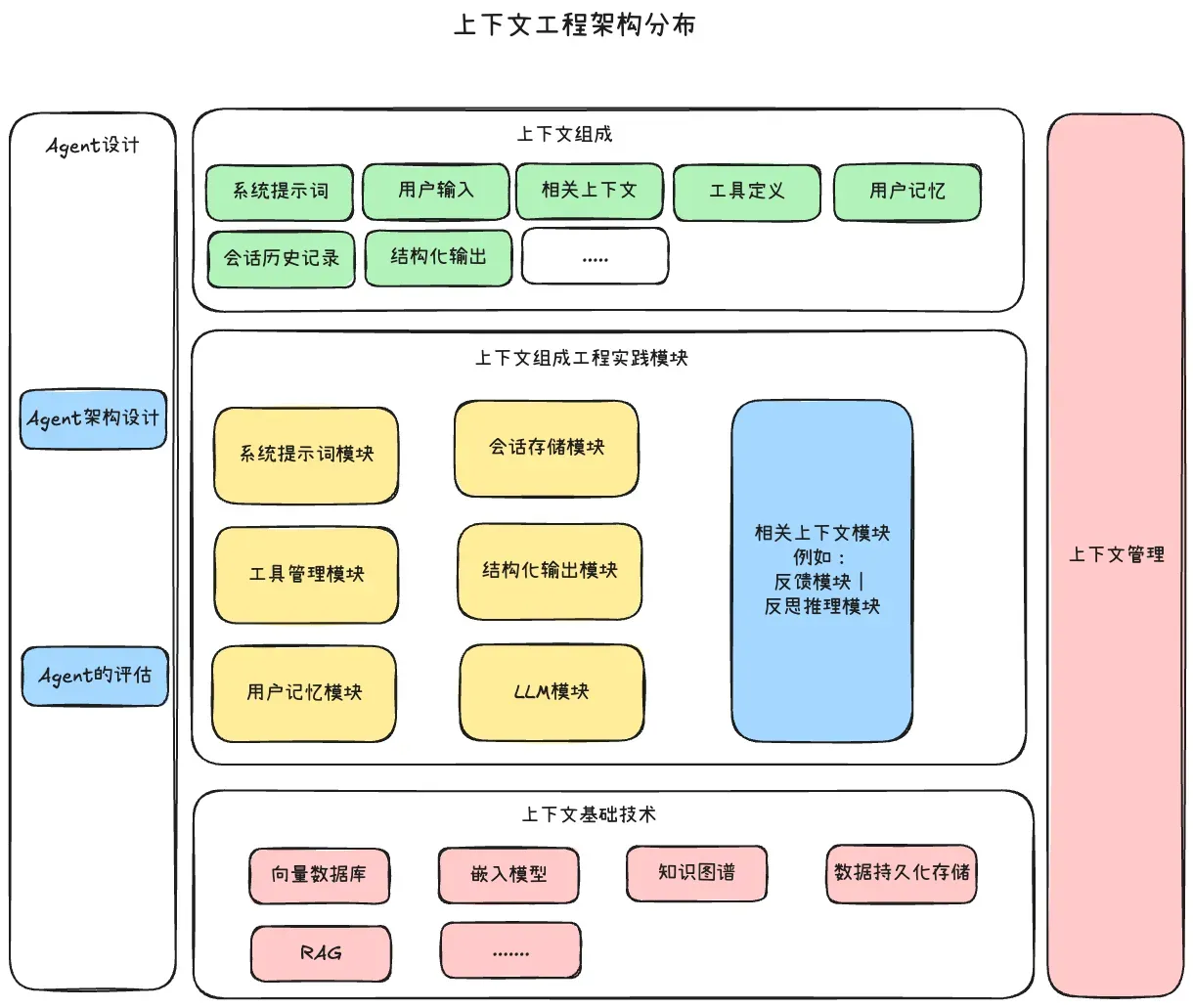
- MCP, skills, tools, and function calling are all ways of connecting external capabilities to the model. Their real purpose is not “tool use” for its own sake, but importing useful external information into context. Underneath that, you still have classic engineering problems: relational queries, vector retrieval, semantic matching, and structured data access.
- User memory and session storage deal with how historical information enters context and how it is read and written efficiently. This opens the door to GraphRAG, file-based memory systems, and layered memory design such as long-term memory, short-term memory, and working memory.
- System prompts are the legacy and continuation of prompt engineering: the effort to define durable behavioral guidance for the model.
- Structured output matters because modules need to exchange information cleanly. When agents collaborate or when outputs are reused as new inputs, structure becomes necessary. That raises practical questions: prompt-based formatting, tool-enforced schemas, parameter-level control, and whether XML, JSON, CSV, or TOML is more model-friendly in a given scenario.
- The LLM layer exists because tools like LangChain or opencode need to adapt to different model providers and API formats. A serious agent system, especially a multi-agent one, needs this adaptation layer.
- Context management includes compression, multi-agent decomposition, collaboration patterns, and the balance between coordinated and autonomous agents.
- Evaluation is what turns iteration into engineering. Whether we are talking about LangFuse-style tracing or prompt update loops, an evaluation layer is what lets the system improve rather than drift.
That brings the whole idea back into focus. The core context types are the starting points for all of this:
- system prompts
- user memory
- tool definitions and tool outputs
- session history
- structured output
- direct user input
Together, these form a complete context package that is injected into the LLM at a particular moment, allowing the model to use its internal reasoning process to complete the task.
In that sense, the job of an LLM application engineer is to ensure that the context injected into the model is precise and effective enough for the model to reason and act well within realistic boundaries.
Since then, I have used this understanding of context engineering as a kind of mental backbone. When a new framework, a new architecture, or a new concept appears, I ask myself: where does it belong in context engineering? Which part of the pipeline does it improve?
That habit has been incredibly useful. It keeps my thinking grounded, and it has also proven effective in the agents I build myself.
Of course, I know this understanding is still partial. There are many technical details and challenges hidden underneath it, and my current framing may eventually become outdated as the field evolves, as models improve, and as better products emerge. That is exactly why flexibility and humility matter.
I hope continued practice will keep sharpening these ideas. Writing them down is part of that process. It is a way of putting them into the open, so that the broader community can help pressure-test them, remove the weak parts, and preserve what is actually useful.
3. Understanding Harness Engineering as Workspace Design
So what does Harness Engineering look like from a context-centered perspective?
For a long time, there was one context type I never felt I could explain clearly enough: what I would call task-relevant context.
My intuition was something like this:
Task-relevant context is one of the hardest things for developers to design well. It is the most variable part of the system, and every agent may need its own architecture for producing it.

When the idea of Harness Engineering appeared, I finally felt that I had a better way to name this missing piece. Task-relevant context is the bridge between Context Engineering and Harness Engineering. It is one of the places where Harness Engineering actually begins.
The articles from OpenAI and Anthropic, in my reading, are not abstract definitions. They are practical accounts of how task-relevant context shows up differently across agents and tasks.
Excalidraw file: https://my.feishu.cn/file/NQLnb4TcXoXDxAxh5AMcSrcQnue
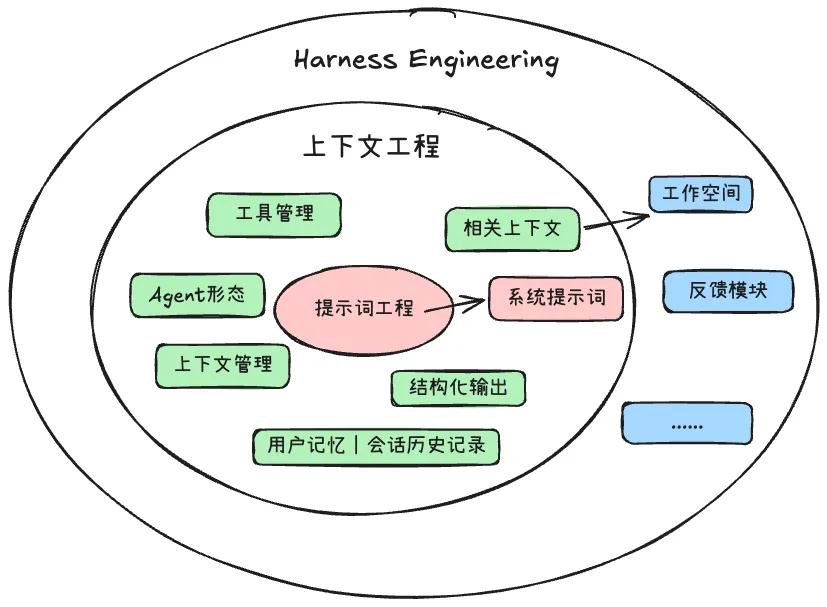
So my own interpretation of Harness Engineering is this:
Harness Engineering is really about defining boundaries and collaboration protocols, not about controlling every individual step of execution.
It is not about limiting what the model can do. It is about creating the conditions under which the model can do things it otherwise could not do.
Engineers should build the workspace in which an agent can operate reliably and effectively inside a given domain.
What matters, then, is not a generic recipe for all agents, but how that workspace is designed in different domains. Inside that workspace, the intermediate artifacts produced by the agent’s execution become the task-relevant context that powers the next step.
OpenAI and Anthropic have already given us valuable references. They are showing, in practice, what kinds of engineering mechanisms and concepts are needed to build long-running agents in the coding domain.
I plan to keep reading those engineering essays carefully and continue refining my own interpretation from them.
4. From “Reasoning” to “Agentic”
Lin Junyang posted an article on X that I found especially interesting, because it was one of the first times I strongly felt that even at the model-training level, a transition is happening. Up to that point, I had mostly been thinking from the application side of the stack.
Earlier in my own experiments with agents, I tried pushing deeper reasoning chains, including multi-agent debate-style reasoning. But I found that this can easily fall into a paradox: trying to reason your way to the right answer from the wrong information.
My current view is that reasoning becomes truly powerful only after context has already been handled as well as possible. Once the task-relevant context is precise enough, reasoning becomes a rocket. Before that, it can just amplify confusion.
That is why I agree with the spirit of the argument that we cannot stay trapped in endless empiricism or endless static reflection. Practice has to keep feeding back into understanding. Sometimes we have to challenge our old mental models and rebuild them.
Human understanding often progresses in a pattern like this: we start from particular cases, expand toward more general patterns, summarize the essential structure, and then return to particular cases with better judgment. Different classes of problems require different large-scale solutions.
If we focus only on the reasoning chain, the model starts to resemble a scholar locked in a study: knowledgeable, capable in some situations, but unable to solve other kinds of problems because it lacks interaction, feedback, and environmental correction.
That is why the move from Reasoning to Agentic systems feels like such a major step. Agentic thinking is about whether a model can keep making progress while interacting with its environment.
In practice, that shows up in a few concrete ways:
- The model decides when to stop thinking and start acting.
- It decides which tools to call and in what order.
- It integrates noisy or incomplete results gathered from the environment.
- It revises its plan after failure.
- It maintains coherence across multi-turn dialogue and repeated tool use.
One line from the original discussion captures the shift especially well:
I expect agentic thinking to become the dominant form of thinking. It may eventually replace most of the old static, monologue-style reasoning, where systems try to compensate for lack of interaction by producing longer and longer internal text. Even on very difficult math or coding tasks, a truly advanced system should be allowed to search, simulate, execute, inspect, verify, and revise. The goal is to solve problems robustly and efficiently.
From the perspective of LLM applications, I read this as another argument for the importance of the agent’s operating space. The harness matters because it shapes how the agent interacts with the external environment.
The real question becomes: how do we build an environment in which an agent can run stably and acquire task-relevant context on its own?
One example is the feedback and verification layer. It gives the agent a way to test itself against the environment. No matter what environment the agent is operating in, it should be able to try things, inspect the feedback signal, and use the completeness of that signal to correct its reasoning and planning. That is how it starts solving problems in a truly grounded way.
Another line from the article puts it beautifully:
Agentic thinking also implies Harness Engineering. More and more of the real intelligence will come from how multiple agents are organized: a coordinator that plans and allocates work, specialist agents that behave like domain experts, and sub-agents that execute narrower tasks while keeping context under control, preventing contamination, and preserving separation between different levels of reasoning. The future moves from training models, to training agents, to training systems.
That, to me, is the real significance of Harness Engineering. It is not a prettier word for control. It is a design problem about workspaces, boundaries, protocols, and the production of task-relevant context.