[Rant] LLMs Are So Powerful That Many People Think They're Experts Now
2 min
AI 总结
$
|
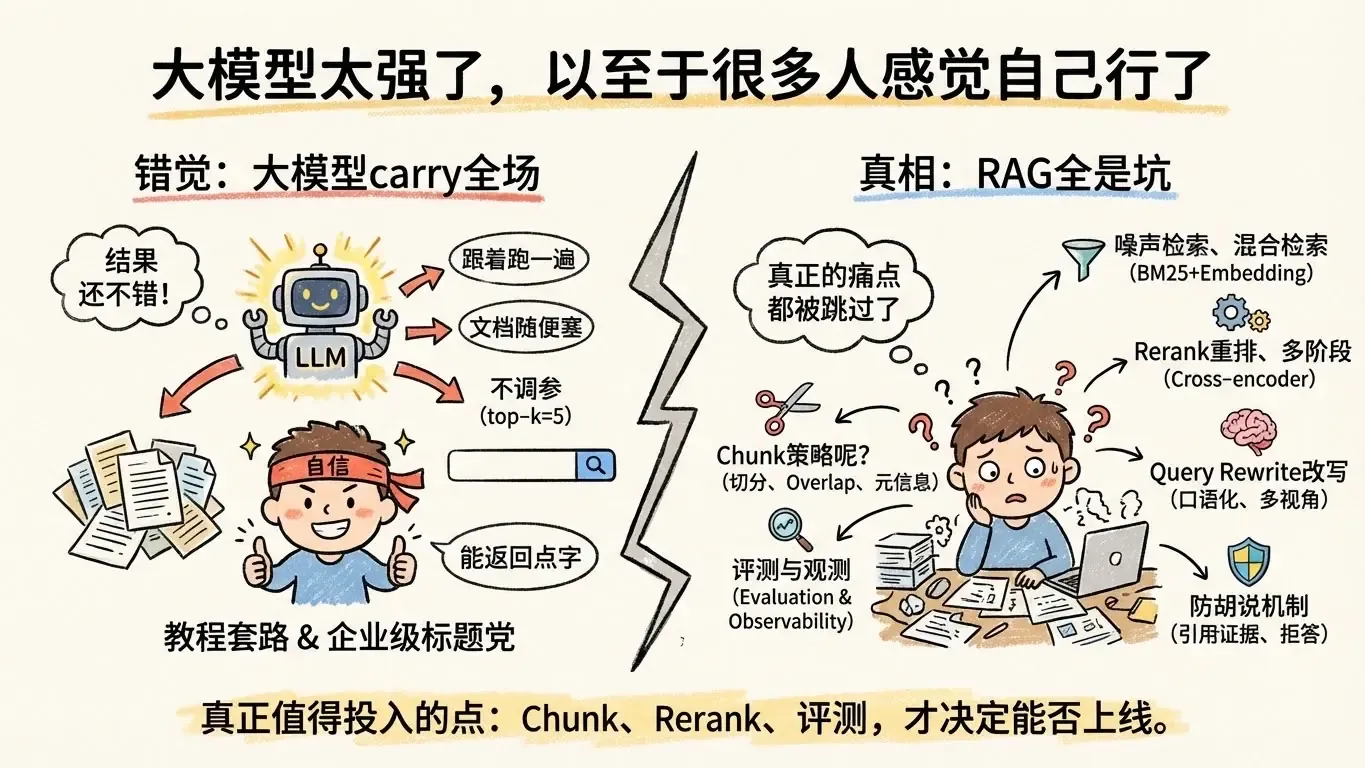
📐 The Common Tutorial Pattern
- Follow the official example → it runs → publish success story.
- Throw documents in randomly, copy default chunk size.
- Keep top-k at 5, never adjust regardless of corpus size or question type.
- No thought process for embedding selection, never check retrieval logs.
- No rerank, no query rewrite, no evaluation discussion.
- No error cases mentioned, just “pip install and you’re done.”
Sure, it runs, but only in the sense that “it returns some text.”
🔥 The Real Pain Points Are All Skipped
- How to chunk without losing information? By paragraph, heading, or structured fields? Any overlap?
- How to reduce noise in retrieval? Any metadata filtering, domain boosting, negative sample training?
- How to weight hybrid retrieval (BM25 + embedding)? What’s the fallback when recall fails?
- Do you need rerank? Multi-modal cross-encoder or lightweight ranker?
- How to improve recall rate? Any incremental building, domain terminology expansion?
- Multi-document fusion order? Any vote / merge-and-reweight?
- When to rewrite user queries? Add clarification when intent is unclear?
- How to ground the final answer? Any chunk citation, traceable evidence?
- How to measure quality? Any offline benchmark, online A/B, error logs?
These are the core of RAG, and tutorials barely mention them.
🏢 “Enterprise-Grade” Clickbait Is Even Worse
I’ve seen many projects claiming to be enterprise-grade RAG:
- No chunk strategy, still “cut every 500 characters.”
- No rerank, no multi-stage retrieval.
- No multi-document processing, no query rewrite.
- Metadata filtering, structured knowledge fusion—all absent.
The results are no different from “PDF search + LLM summary,” but the titles are more ambitious than the solutions.
🔍 No Evaluation = No Production Readiness
What should really be written about is evaluation and observability:
- What’s the actual recall rate? Broken down by data domain?
- How does the model respond when it can’t retrieve content? Any fallback, refusal strategy?
- What’s the noise chunk ratio? Does the ranker actually work?
- Does document fusion turn sections into mush?
- Does the prompt guide citation sources, limit hallucination?
- Which question types fail most often? Manuals, policies, numbers, or real-time info?
Without these metrics, “enterprise-grade” is just self-congratulation.
🧭 What’s Actually Worth Investing In
- Chunk strategy: Cut by structure, set overlap, preserve metadata, build dual indexes (paragraph + table) when necessary.
- Multi-stage retrieval: BM25 coarse filter first, then embedding fine recall, finally rerank, introduce domain knowledge graph when needed.
- Rerank: Use cross-encoder, linear reranking, or rule-based rerank to filter out noise first.
- Query rewrite: Rewrite colloquial, misspelled, context-missing queries, can also do multi-perspective queries.
- Document fusion: Set evidence count, ordering, citation format, avoid merging multiple sources into unsourced paragraphs.
- Evaluation: Build golden Q&A sets offline, track recall rate, hit rate, refusal rate online.
- Observability: Log retriever hit documents, ranker scores, LLM final answers for review.
- Prevent hallucination: Cite evidence, limit answer templates, set hard rule “refuse to answer if retrieval fails.”
These determine whether a RAG can actually go to production.
Pure rant, don’t take it personally.