【吐槽】大模型太强了,以至于很多人感觉自己行了
4 min
AI 总结
$
|
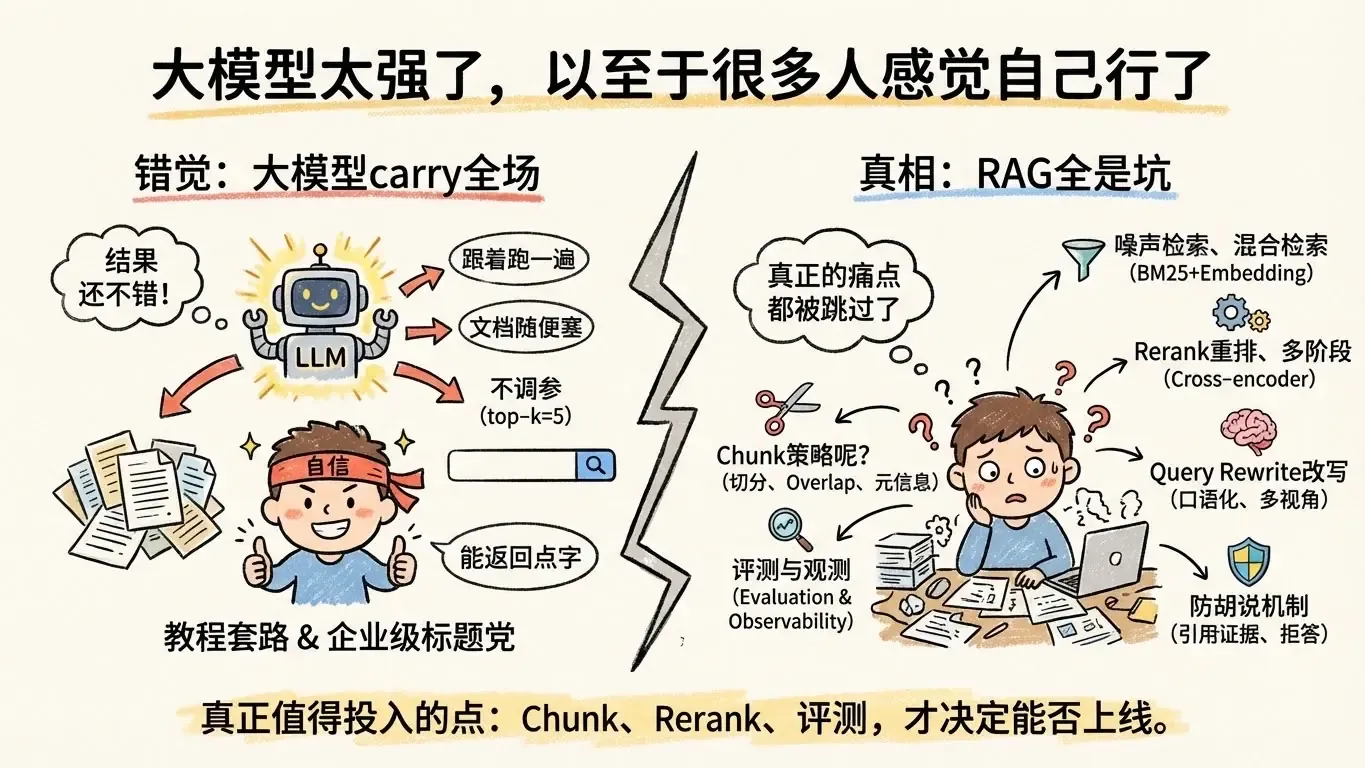
📐 教程的共同套路
- 跟着官方示例走一遍 → 跑起来了 → 发布战报。
- 文档随便往里塞,chunk 尺寸抄默认。
- top-k 恒定 5,无论语料规模、问题类型都不调。
- embedding 选型思路没有,检索日志也不看。
- 不 rerank、不 query rewrite、不谈 evaluation。
- 不讲 error case,只会贴一句 “pip install 一下即可。”
最后确实能跑,但仅限于“能返回点字”。
🔥 真正的痛点都被跳过了
- chunk 怎么切才不丢信息?是按段落、标题,还是结构化字段?有没有做 overlap?
- 如何减少噪声检索?有没有 metadata 过滤、domain boost、负样本训练?
- 混合检索(BM25 + embedding)怎么配权?召回失败时 fallback 是什么?
- 需不需要 rerank?是多模态 cross-encoder 还是轻量 ranker?
- 召回率如何提升?有没有增量构建、领域术语扩展?
- 多文档融合顺序?是否做 vote / merge-and-reweight?
- 用户问句何时改写?意图不明时是否加 Clarification?
- 最终回答如何 grounding?有没 cite chunk、可追溯的 evidence?
- 衡量好坏靠什么?有没有离线 benchmark、在线 A/B、error log?
这些才是 RAG 的核心,教程基本一字不提。
🏢 “企业级”标题党更离谱
我看到不少号称企业级 RAG 的项目:
- chunk 策略没有,仍旧“每 500 字切一刀”。
- rerank 没有,多阶段检索也没有。
- 多文档处理没有,query rewrite 没有。
- metadata 过滤、结构化知识融合统统缺席。
跑出来的效果跟“PDF 搜索 + LLM 总结”没区别,但标题写得比方案还飞。
🔍 没评测 = 没上线资格
真正该写的,是评测与观测:
- 召回率到底多少?分数据域拆开了吗?
- 捞不到内容时模型会怎么答?有没有 fallback、拒答策略?
- 噪声 chunk 比例多大?排序器真有效吗?
- 文档融合会不会把章节搅成粥?
- prompt 有没有引导引用来源、限制胡说八道?
- 哪类问题最容易翻车?操作手册、政策、数值还是实时信息?
没有这些指标,所谓“企业级”只是自嗨。
🧭 真正值得投入的点
- chunk 策略:按结构切、设置 overlap、保留元信息,必要时构建双索引(段落 + 表格)。
- 多阶段检索:先 BM25 粗筛、再 embedding 精召回、最后 rerank,必要时引入领域知识图谱。
- rerank:使用 cross-encoder、线性重排或规则 rerank,让噪声先滚出去。
- query rewrite:对口语化、拼写错误、上下文缺失的问句重写,还可做多视角查询。
- 文档融合:设定 evidence 数量、排序、引用格式,避免把多个来源黏成无出处的段落。
- evaluation:离线构造黄金问答集,在线埋点统计召回率、命中率、拒答率。
- observability:记录 retriever 命中文档、ranker 分数、LLM 最终回答,方便复盘。
- 防胡说:引用证据、限制回答模板、设置“检索失败就拒答”的硬规则。
这些才决定一个 RAG 到底能不能上线。
纯吐槽,切勿对号入座。